
Accelerate AI Integration
for Your Products
Accelerate AI Integration
for Your Products
Accelerate AI Integration
for Your Products
Accelerate AI Integration
for Your Products
OmniStack equips devs / teams with the infrastructure and tools to deploy, trace, manage prompts, evaluate, build pipelines, and maintain high uptime for your AI applications and agentic needs.
OmniStack equips devs / teams with the infrastructure and tools to deploy, trace, manage prompts, evaluate, build pipelines, and maintain high uptime for your AI applications and agentic needs.


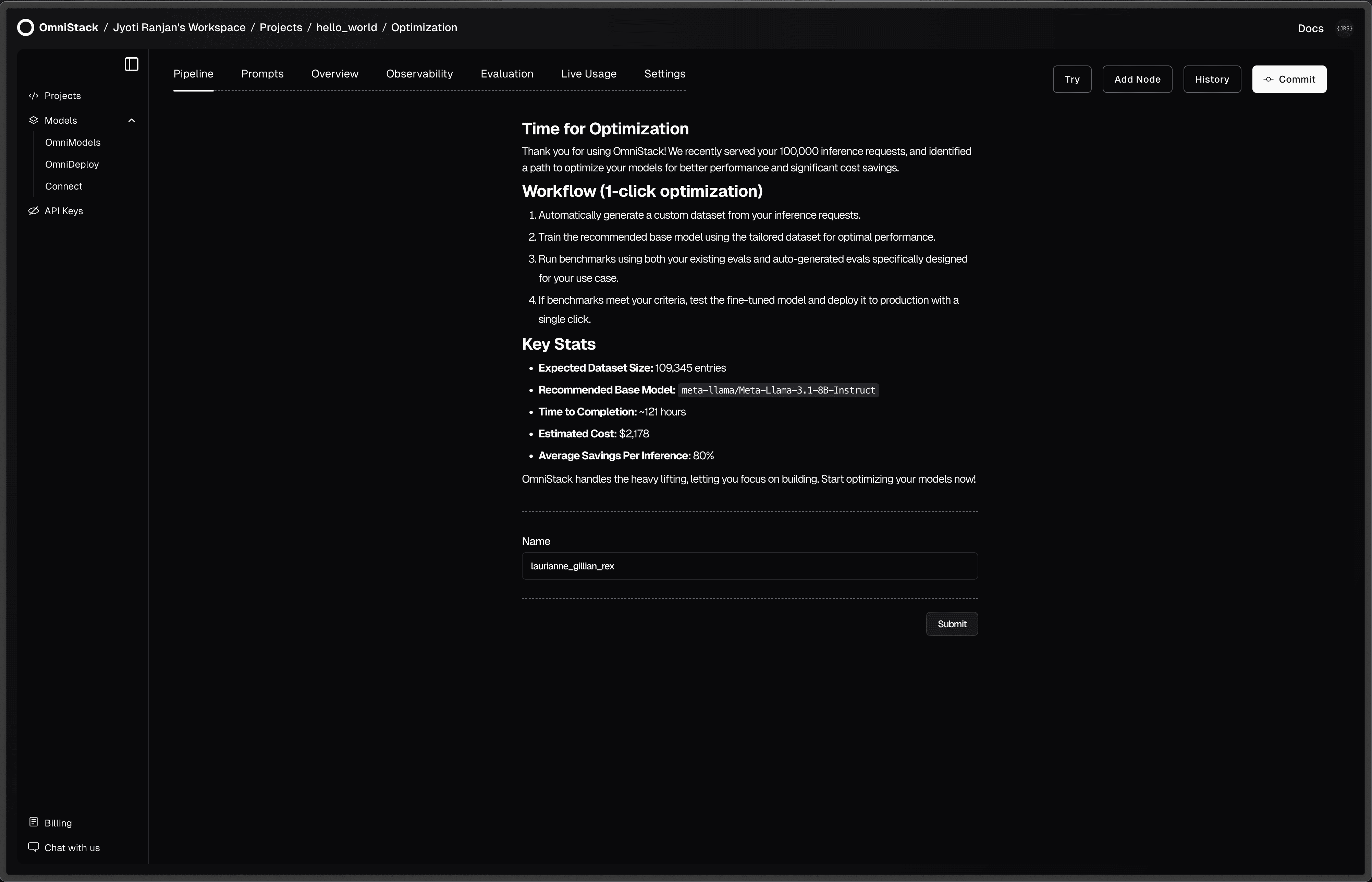
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
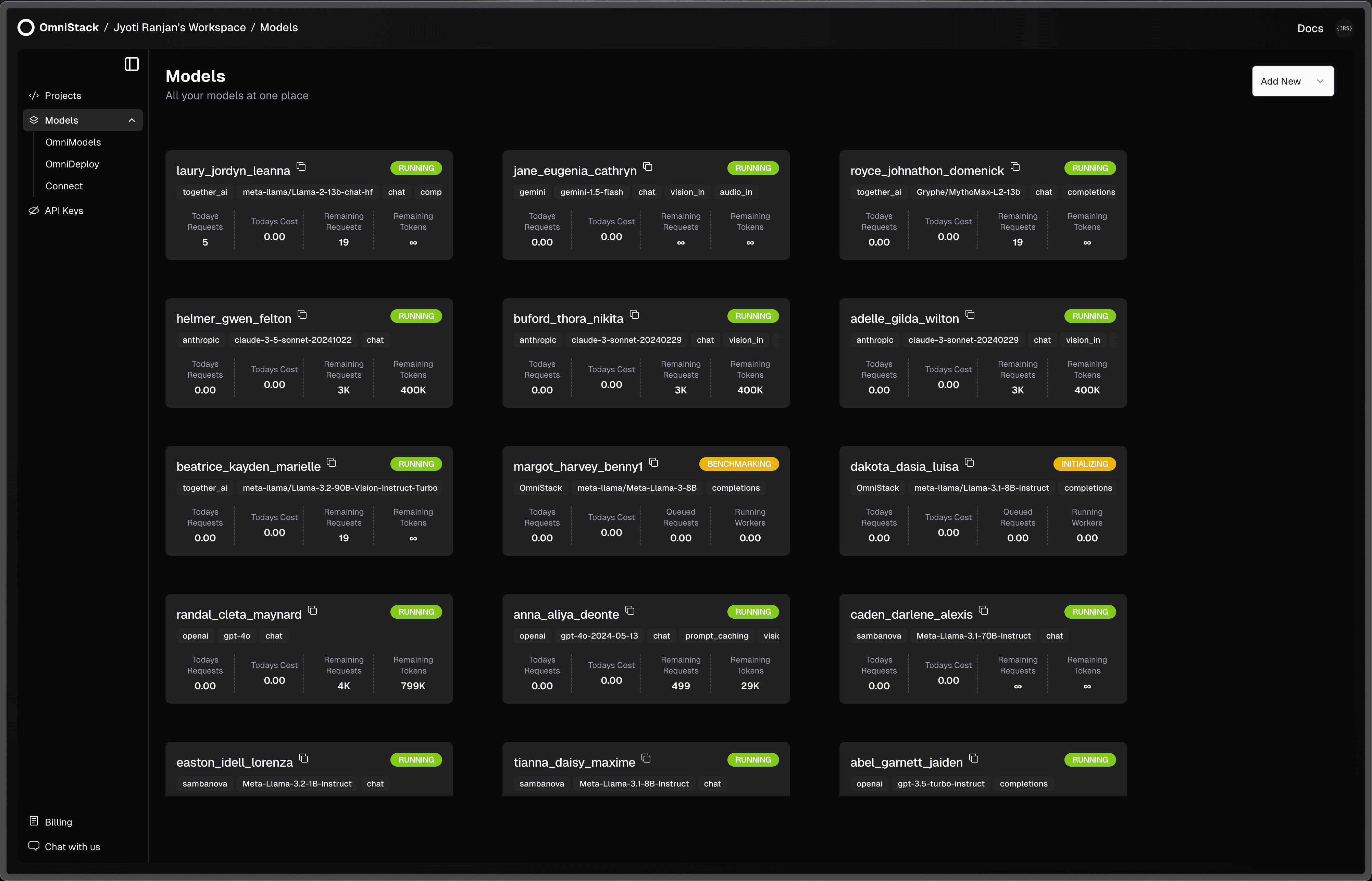
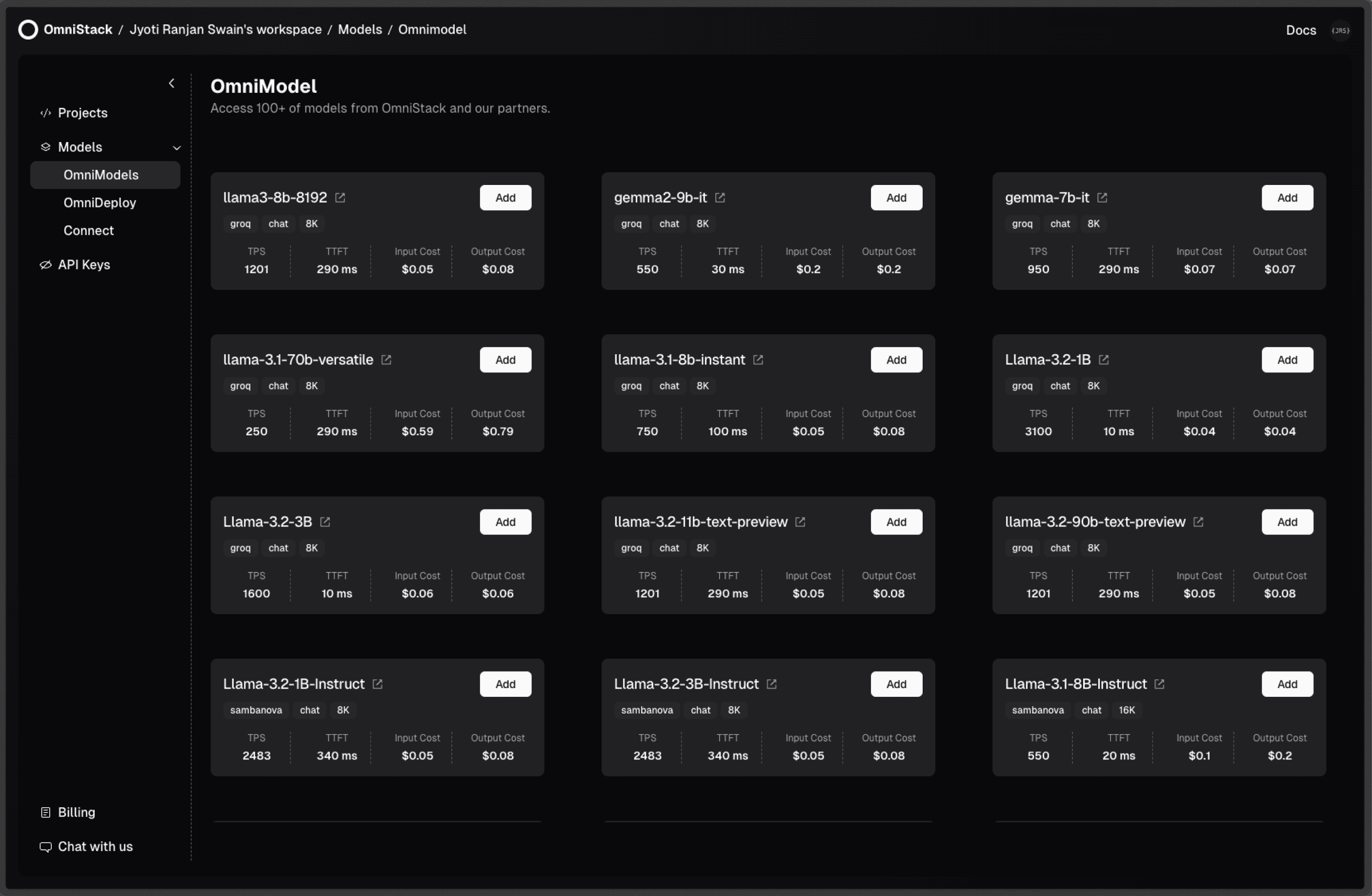
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
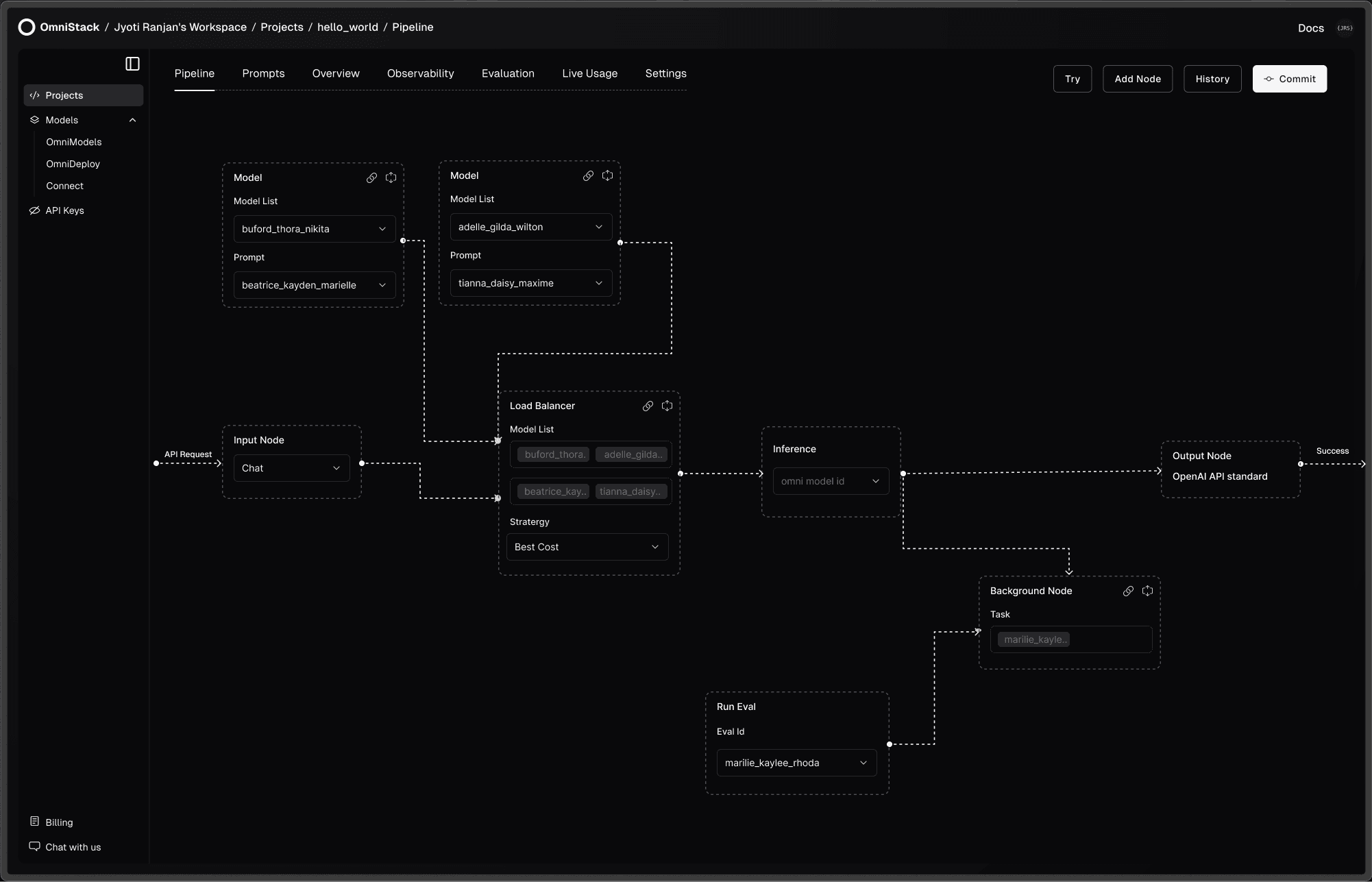
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
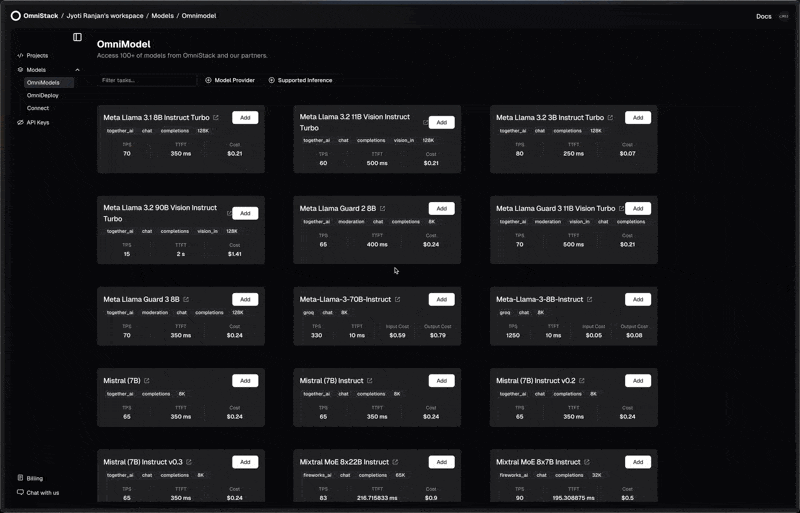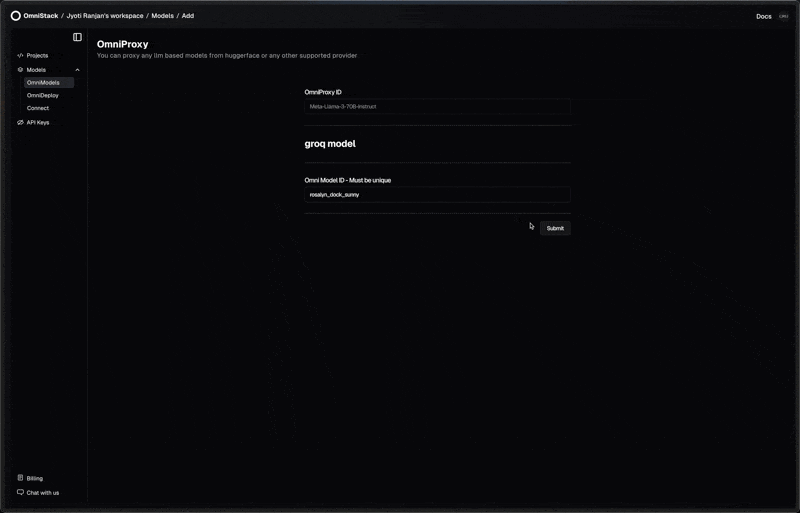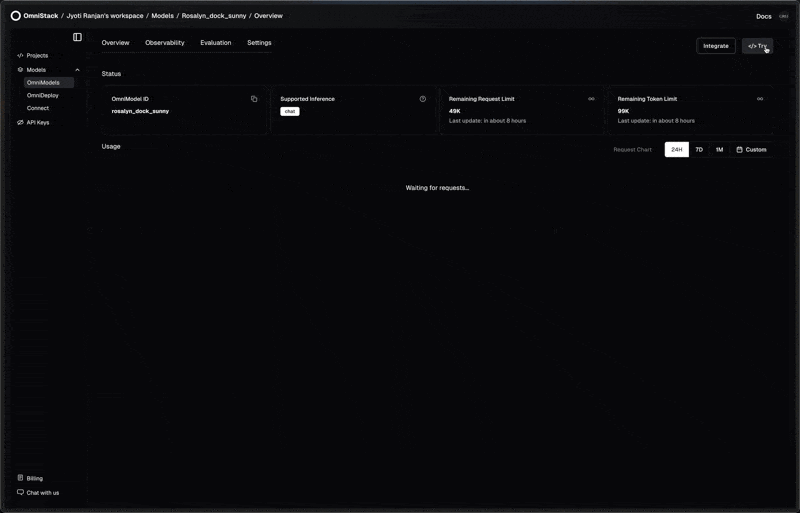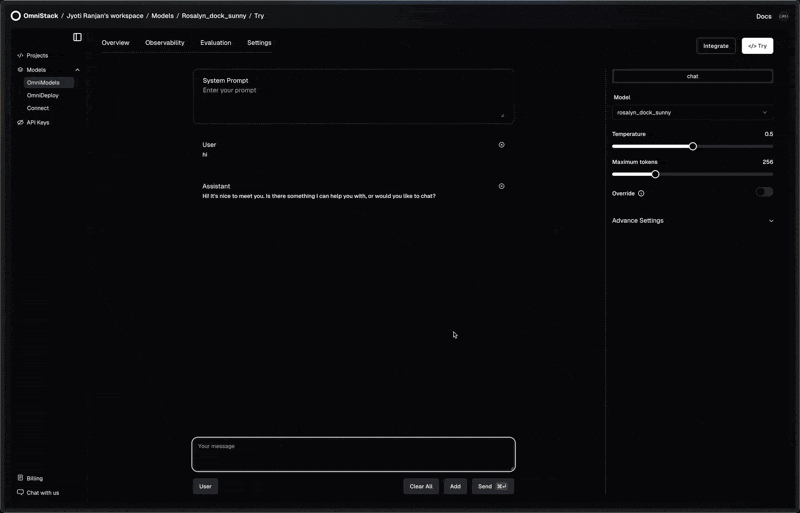
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.

Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.

Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Our platform
OmniModels
OmniDeploy
PIpeline
Overview
Observability
Evaluation
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Our platform
OmniModels
OmniDeploy
PIpeline
Overview
Observability
Evaluation
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Our platform
OmniModels
OmniDeploy
PIpeline
Overview
Observability
Evaluation
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
Our platform
OmniModels
OmniDeploy
PIpeline
Overview
Observability
Evaluation
Usage-Based AI Optimization Alerts
OmniStack analyzes your usage, providing real-time alerts and cost-saving recommendations like fine-tuning models or auto-generating evaluations to boost efficiency.
OmniModels: Ready-to-Use AI Models
Access preconfigured LLMs from OpenAI, Anthropic, etc and in-house deployed models, ready to use instantly without any setup hassle.
OmniDeploy: Effortless AI Deployment
Deploy generative AI models from Hugging Face on serverless GPU infrastructure or opt for dedicated GPU clusters and LPUs for larger models or high-throughput applications.
Pipeline: Inference Workflows
Design inference workflows with ease—set up load balancing by latency, cost etc, add fallbacks, run background evaluations, or build complete agentic workflows via GUI or code.
Observability: Complete Inference Insights
Gain complete visibility into every step—track costs, rate limits, and debug inference requests with detailed insights and traceability.
Evals: Automated Model Testing
Run evaluations on past logs, datasets, or live requests in the background, and receive alerts when performance falls outside the criteria range.
Prompt Management: Git for Prompts
Design, experiment, evaluate, and deploy prompts seamlessly—bringing Git-style version control to prompt engineering.
The Inference Engine For Developers
The Inference Engine For Developers
The Inference Engine For Developers